2019年3月,百度正式發(fā)布 NLP 模型 ERNIE,其在中文任務(wù)中全面超越 BERT 一度引發(fā)業(yè)界廣泛關(guān)注和探討。
今天,經(jīng)過短短幾個(gè)月時(shí)間,百度 ERNIE 再升級。發(fā)布持續(xù)學(xué)習(xí)的語義理解框架 ERNIE 2.0,及基于此框架的 ERNIE 2.0預(yù)訓(xùn)練模型。繼1.0后,ERNIE 英文任務(wù)方面取得全新突破,在共計(jì)16個(gè)中英文任務(wù)上超越了 BERT 和 XLNet, 取得了 SOTA 效果。
目前,百度 ERNIE 2.0的 Fine-tuning 代碼和英文預(yù)訓(xùn)練模型已開源。( Github 項(xiàng)目地址:https://github.com/PaddlePaddle/ERNIE)
近兩年,以 BERT 、 XLNet 為代表的無監(jiān)督預(yù)訓(xùn)練技術(shù)在語言推斷、語義相似度、命名實(shí)體識別、情感分析等多個(gè)自然語言處理任務(wù)上取得了技術(shù)突破。基于大規(guī)模數(shù)據(jù)的無監(jiān)督預(yù)訓(xùn)練技術(shù)在自然語言處理領(lǐng)域變得至關(guān)重要。
百度發(fā)現(xiàn),之前的工作主要通過詞或句子的共現(xiàn)信號,構(gòu)建語言模型任務(wù)進(jìn)行模型預(yù)訓(xùn)練。例如,BERT 通過掩碼語言模型和下一句預(yù)測任務(wù)進(jìn)行預(yù)訓(xùn)練。XLNet 構(gòu)建了全排列的語言模型,并通過自回歸的方式進(jìn)行預(yù)訓(xùn)練。
然而,除了語言共現(xiàn)信息之外,語料中還包含詞法、語法、語義等更多有價(jià)值的信息。例如,人名、地名、機(jī)構(gòu)名等詞語概念知識,句子間順序和距離關(guān)系等結(jié)構(gòu)知識,文本語義相似度和語言邏輯關(guān)系等語義知識。設(shè)想如果能持續(xù)地學(xué)習(xí)各類任務(wù),模型的效果能否進(jìn)一步提升?
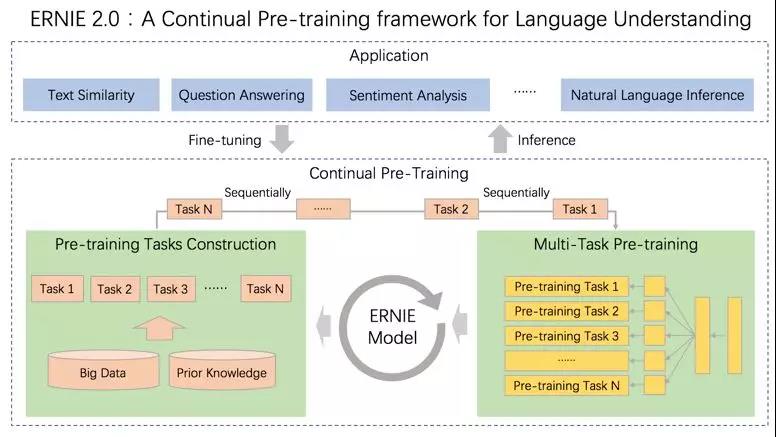
▲ERNIE 2.0:可持續(xù)學(xué)習(xí)語義理解框架
基于此,百度提出可持續(xù)學(xué)習(xí)語義理解框架 ERNIE 2.0。該框架支持增量引入詞匯( lexical )、語法 ( syntactic ) 、語義( semantic )等3個(gè)層次的自定義預(yù)訓(xùn)練任務(wù),能夠全面捕捉訓(xùn)練語料中的詞法、語法、語義等潛在信息。
這些任務(wù)通過多任務(wù)學(xué)習(xí)對模型進(jìn)行訓(xùn)練更新,每當(dāng)引入新任務(wù)時(shí),該框架可在學(xué)習(xí)該任務(wù)的同時(shí),不遺忘之前學(xué)到過的信息。這也意味著,該框架可以通過持續(xù)構(gòu)建訓(xùn)練包含詞法、句法、語義等預(yù)訓(xùn)練任務(wù),持續(xù)提升模型效果。
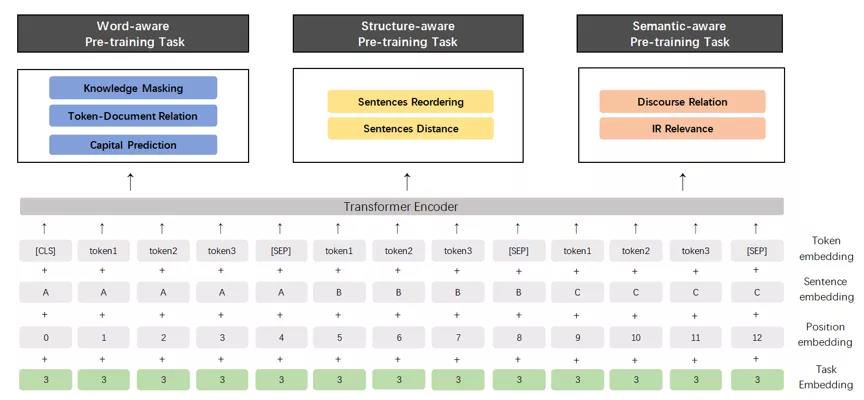
▲新發(fā)布的 ERNIE 2.0模型結(jié)構(gòu)
依托該框架,百度充分借助飛槳 PaddlePaddle 多機(jī)分布式訓(xùn)練優(yōu)勢,利用 79億 tokens 訓(xùn)練數(shù)據(jù)(約1/4的 XLNet 數(shù)據(jù))和64張 V100(約1/8的 XLNet 硬件算力)訓(xùn)練的 ERNIE 2.0預(yù)訓(xùn)練模型不僅實(shí)現(xiàn)了 SOTA 效果,而且為開發(fā)人員定制自己的 NLP 模型提供了方案。目前,百度開源了 ERNIE 2.0的 Fine-tuning 代碼和英文預(yù)訓(xùn)練模型。
百度研究團(tuán)隊(duì)分別比較了中英文環(huán)境上的模型效果。英文上,ERNIE 2.0在自然語言理解數(shù)據(jù)集 GLUE 的7個(gè)任務(wù)上擊敗了 BERT 和 XLNet。中文上,在包括閱讀理解、情感分析、問答等不同類型的9個(gè)數(shù)據(jù)集上超越了 BERT 并刷新了 SOTA。
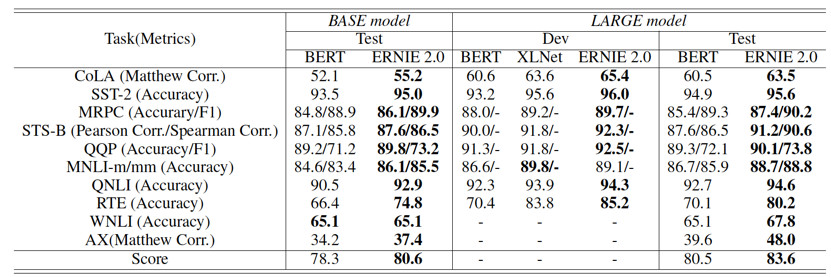
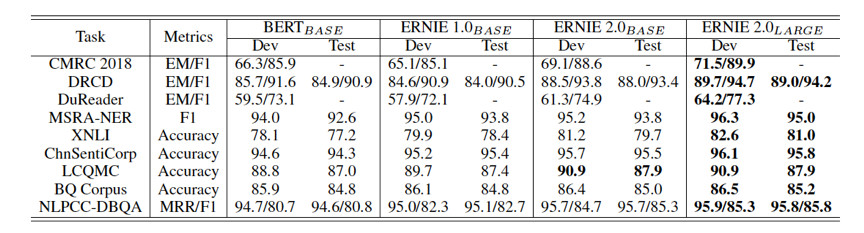
ERNIE 的工作表明,在預(yù)訓(xùn)練過程中,通過構(gòu)建各層面的無監(jiān)督預(yù)訓(xùn)練任務(wù),模型效果也會顯著提升。未來,研究者們可沿著該思路構(gòu)建更多的任務(wù)提升效果。
自2018 年預(yù)訓(xùn)練語言模型 BERT 提出之后,預(yù)訓(xùn)練語言模型將自然語言處理的大部分任務(wù)水平提高了一個(gè)等級,這個(gè)領(lǐng)域的研究也掀起了熱潮。如今可持續(xù)學(xué)習(xí)的特點(diǎn)亦將成為 NLP 領(lǐng)域發(fā)展里程中的關(guān)鍵。
來源 | 百度AI









