集體智能(collective intelligence)是人工智能研究浪潮中不可被忽視的重要課題。然而,智能體如何在邊界開放、約束動(dòng)態(tài)的環(huán)境下學(xué)習(xí)到知識(shí),并且進(jìn)行團(tuán)隊(duì)協(xié)作仍然是極具挑戰(zhàn)的難題。DeepMind 近年來針對基于種群的多智能體強(qiáng)化學(xué)習(xí)進(jìn)行了大量的研究,其最新研究成果近日發(fā)表在了國際權(quán)威雜志「Science」上。DeepMind 發(fā)博客將這一成果進(jìn)行了介紹,雷鋒網(wǎng) AI 科技評論編譯如下.
智能體在多玩家電子游戲中掌握策略、理解戰(zhàn)術(shù)以及進(jìn)行團(tuán)隊(duì)協(xié)作是人工智能研究領(lǐng)域的重大挑戰(zhàn)。我們發(fā)表在「科學(xué)」雜志上的最新論文「Human-level performance in 3D multiplayer games with population-based reinforcement learning」中,展示了智能體在強(qiáng)化學(xué)習(xí)領(lǐng)域的最新進(jìn)展,在「Quake III Arena」奪旗賽(CTF)中取得了與人類水平相當(dāng)?shù)男阅堋_@是一個(gè)復(fù)雜的多智能體環(huán)境,也是第一人稱多玩家的經(jīng)典三維游戲之一。這些智能體成功地與 AI 隊(duì)友和人類隊(duì)友協(xié)作,表現(xiàn)出了很高的性能,即使在訓(xùn)練時(shí)其反應(yīng)時(shí)間,表現(xiàn)也與人類相當(dāng)。此外,我們還展示了如何能夠成功地將這些方法從研究 CTF 環(huán)境中擴(kuò)展到完整的「Quake III Arena」游戲中。
論文地址(Science):https://science.sciencemag.org/cgi/doi/10.1126/science.aau6249

玩CTF游戲的智能體,以其中一個(gè)紅色玩家為第一人稱視角展現(xiàn)的室內(nèi)環(huán)境(左圖)和室外環(huán)境(右圖)。

智能體在完整的錦標(biāo)賽地圖上的另外兩個(gè)「Quake III Arena」多人游戲模式下進(jìn)行游戲:在「Future Crossings」地圖上進(jìn)行收割者模式的游戲(左圖),在「ironwood」地圖上進(jìn)行單旗奪旗模式的游戲(右圖),在游戲中可以拾取并使用完整版游戲的所有的道具。
目前,有數(shù)十億人居住在地球上,每個(gè)人都有自己獨(dú)特的目標(biāo)和行為。但人們?nèi)匀荒軌蛲ㄟ^團(tuán)隊(duì)、組織和社會(huì)團(tuán)結(jié)在一起,展示出非凡的集體智能。我們將這種情況稱為多智能體學(xué)習(xí):許多獨(dú)立的智能體必須各自單獨(dú)行動(dòng),但同時(shí)也要學(xué)會(huì)與其它的智能體進(jìn)行交互和協(xié)作。這是一個(gè)非常困難的問題,因?yàn)樾枰獏f(xié)同適應(yīng)其他的智能體,它們所處的世界環(huán)境就會(huì)不斷變化。
為了研究這個(gè)問題,我們著眼于第一人稱的多人三維電子游戲。這些游戲也代表著目前最流行的一類電子游戲,由于能夠?yàn)橛脩籼峁┏两降挠螒蝮w驗(yàn),這類游戲充分開發(fā)了數(shù)百萬玩家的想象力,同時(shí)也對玩家在策略、戰(zhàn)術(shù)、手眼協(xié)調(diào)以及團(tuán)隊(duì)協(xié)作等方面提出了挑戰(zhàn)。我們的智能體所面臨的挑戰(zhàn)便是直接利用原始像素來生成決策行為。這種復(fù)雜性也使得第一人稱多人游戲在人工智能研究領(lǐng)域中成為了一個(gè)碩果累累、朝氣蓬勃的研究領(lǐng)域。
奪旗賽:根據(jù)像素做出動(dòng)作決策
在這項(xiàng)研究中,我們聚焦于「Quake III Arena」游戲(在保證所有的游戲機(jī)制維持不變的情況下,我們對美工進(jìn)行了微調(diào))。「Quake III Arena」是許多現(xiàn)代第一人稱電子游戲的奠基者,曾經(jīng)在電子競技舞臺(tái)上風(fēng)靡一時(shí)。我們訓(xùn)練智能體像人類玩家一樣學(xué)習(xí)和行動(dòng),但是它們必須能夠以團(tuán)隊(duì)協(xié)作的方式與其它智能體(無論是 AI 玩家還是人類玩家)合作或?qū)埂?/p>
CTF 的規(guī)則很簡單,但是其動(dòng)態(tài)變化則非常復(fù)雜。兩隊(duì)獨(dú)立的玩家比賽的方式是:在給定的地圖上以奪取對方隊(duì)伍的旗幟為目標(biāo),同時(shí)保護(hù)他們自己的旗幟。為了獲得戰(zhàn)術(shù)上的優(yōu)勢,玩家可以攻擊對方戰(zhàn)隊(duì)的玩家,將其送回復(fù)活點(diǎn)。在 5 分鐘的游戲時(shí)間結(jié)束后,獲得旗幟數(shù)量最多的隊(duì)伍將獲得勝利。
從多智能體的視角來說,CTF 要求玩家同時(shí)做到與他們的隊(duì)友通力合作以及與對手的隊(duì)伍進(jìn)行對抗,并且還要對它們可能遇到的任何比賽方式都要保持魯棒性。
為了讓這個(gè)工作變得更有趣,我們還考慮了一個(gè) CTF 的變體形式,其中的地圖布局每經(jīng)過一場比賽就會(huì)變化。結(jié)果,我們的智能體被迫獲取通用的策略,而不是記住地圖的布局。此外,為了競爭的公平性,我們的智能體在學(xué)習(xí)過程中以與人類相似的方式對 CTF 的世界進(jìn)行探索:他們會(huì)觀察一組圖像的像素流,然后通過模擬的游戲控制器采取行動(dòng)。

在程序生成的環(huán)境中進(jìn)行CTF,這樣一來智能體的能力必須能夠泛化到?jīng)]有見過的地圖上。
我們的智能體必須從頭開始學(xué)會(huì)如何觀察環(huán)境、執(zhí)行動(dòng)作、協(xié)作以及在未見過的環(huán)境中競爭,而所有這些都學(xué)習(xí)自每場比賽的單個(gè)強(qiáng)化信號(hào):它們的團(tuán)隊(duì)是否獲勝。這是一個(gè)極具挑戰(zhàn)的學(xué)習(xí)問題,其解決方案是以如下強(qiáng)化學(xué)習(xí)的三種通用思想為基礎(chǔ)的:
- 我們訓(xùn)練的是一個(gè)智能體種群,而不是訓(xùn)練單個(gè)智能體。種群中的智能體通過與其它智能體進(jìn)行游戲來學(xué)習(xí)。在游戲中,智能體彼此之間的關(guān)系是多種多樣的,可能是隊(duì)友也可能是對手。
- 種群中的每個(gè)智能體都需要學(xué)習(xí)他們自己的內(nèi)部獎(jiǎng)勵(lì)信號(hào),這使得智能體可以生成他們自己的內(nèi)部目標(biāo)(例如奪取旗幟)。我們使用雙層優(yōu)化處理的方式來優(yōu)化智能體的內(nèi)部獎(jiǎng)勵(lì),從而直接獲勝,并且運(yùn)用基于內(nèi)部獎(jiǎng)勵(lì)的強(qiáng)化學(xué)習(xí)技術(shù)來學(xué)習(xí)智能體的游戲策略。
- 智能體分別以快速和慢速兩種游戲時(shí)標(biāo)進(jìn)行操作,這有助于提升它們使用內(nèi)存和生成一致的動(dòng)作序列的能力。

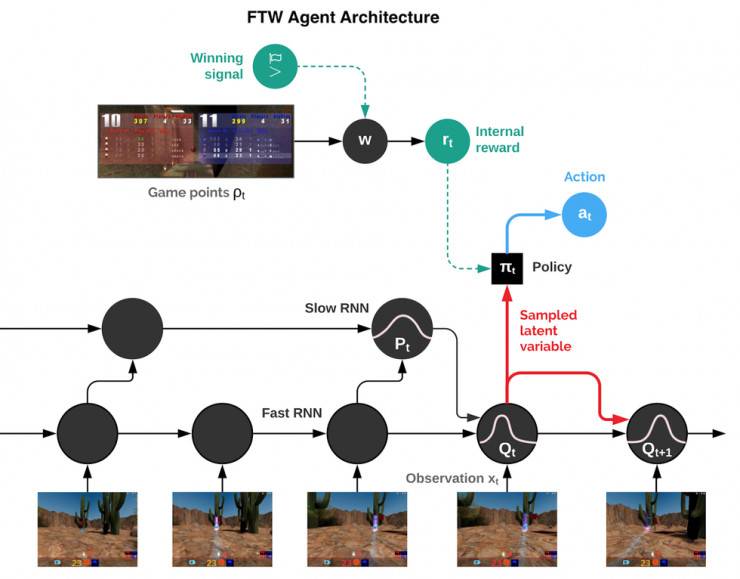
「為了勝利」(FTW)智能體的架構(gòu)示意圖。該智能體融合了快速和慢速兩種時(shí)標(biāo)的循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN),包括一個(gè)共享的內(nèi)存模塊,并且學(xué)習(xí)了從游戲點(diǎn)到內(nèi)部獎(jiǎng)勵(lì)的轉(zhuǎn)換。
最終得到的智能體被稱為 FTW 智能體,他們學(xué)著以非常高的水平外 CTF 游戲。非常重要的一點(diǎn)是,學(xué)習(xí)到的智能體策略對于地圖的尺寸、隊(duì)友的數(shù)量、以及隊(duì)伍中的其他成員等參數(shù)變化需要具備魯棒性。下面,你可以探索一些戶外程序環(huán)境的游戲(其中 FTW 智能體相互對抗),也可以探索一些人類和智能體在室內(nèi)程序環(huán)境中一起玩的游戲。

交互式的 CTF 游戲探索器,具有程序生成的室內(nèi)和室外兩種環(huán)境。室外地圖上的游戲在 FTW 智能體之間開展,而室內(nèi)地圖上的游戲則是人類和 FTW 智能體玩家的混合游戲。
我們進(jìn)行了一場包括 40 名人類玩家的游戲比賽,在比賽中人類玩家和智能體隨機(jī)配對,既有可能成為對手,也可能成為隊(duì)友。

早先的一場測試比賽,對戰(zhàn)雙方是人類 CTF 玩家和受過訓(xùn)練的其他人類玩家和智能體。
FTW 智能體通過學(xué)習(xí)變得比強(qiáng)基線方法強(qiáng)大得多,并且超過了人類玩家的勝率。事實(shí)上,在一份針對游戲參與者的調(diào)查中,它們比人類參與者表現(xiàn)出了更高的協(xié)作性。

我們的智能體在訓(xùn)練時(shí)的性能。我們的新 FTW 智能體,獲得了比人類玩家和基線方法(Self-play + RS 和 Self-play)高得多的 Elo 等級(jí)分(對應(yīng)獲勝概率)。
除了對模型性能進(jìn)行評估,理解這些智能體的行為及內(nèi)部表征的復(fù)雜度也非常重要。
為了理解智能體如何表示游戲狀態(tài),我們對智能體神經(jīng)網(wǎng)絡(luò)的激活模式進(jìn)行了研究,并且將其繪制在一個(gè)平面上。在下圖中,一群群的點(diǎn)代表在游戲中的各種情景,相鄰的點(diǎn)則代表相似的激活模式。我們根據(jù)高水平的 CTF 游戲狀態(tài)來對這些點(diǎn)進(jìn)行著色,這些狀態(tài)包括:智能體在哪個(gè)房間中?旗幟的狀態(tài)如何?可以看到哪些隊(duì)友和對手?我們觀察到的顏色相同的點(diǎn)簇,這代表的是智能體以相似的方式表示相似的高水平游戲狀態(tài)。

我們的智能體是如何表征游戲世界的?在上圖中,我們根據(jù)每個(gè)代表神經(jīng)激活模式的點(diǎn)與其它點(diǎn)的相似程度繪制出了某時(shí)刻的神經(jīng)激活模式示意圖:在空間中距離越近的兩個(gè)點(diǎn)的激活模式越相似。接著,我們會(huì)根據(jù)它們在該時(shí)刻的情景對其進(jìn)行著色——相同的顏色代表相同的情景。我們可以看到,這些神經(jīng)元激活模式被組織了起來,形成了不同顏色的簇,這意味著智能體確實(shí)以一種有規(guī)則的、有組織的方式表示游戲玩法的某些有意義的因素。這些訓(xùn)練后的智能體甚至展示出了一些直接對特定情況編碼的人工神經(jīng)元。
智能體從未被告知任何有關(guān)游戲規(guī)則的信息,它們需要學(xué)習(xí) CTF 的基本游戲概念并發(fā)展出自己有效的直覺。事實(shí)上,我們可以發(fā)現(xiàn),某些特定的神經(jīng)元會(huì)直接對最重要的游戲狀態(tài)進(jìn)行編碼(例如,當(dāng)智能體的旗幟被奪走時(shí)或智能體的隊(duì)友奪到旗幟時(shí),某個(gè)神經(jīng)元就會(huì)被激活)。我們的論文針對智能體對內(nèi)存的利用和視覺注意力機(jī)制的使用進(jìn)行了進(jìn)一步的分析。
表現(xiàn)與人類相媲美的智能體
我們的智能體在游戲中的表現(xiàn)如何,又是如何采取行動(dòng)的呢?
首先,我們注意到智能體的反應(yīng)時(shí)間非常短,并且攻擊十分精準(zhǔn),這或許就解釋了他們?yōu)槭裁磿?huì)有如此出色的表現(xiàn)(「攻擊」是一種戰(zhàn)術(shù)行為,能夠?qū)κ炙突氐剿麄兊某霭l(fā)點(diǎn))。人類對于這些感官輸入的處理和反應(yīng)速度相對來說要慢一些,這是因?yàn)槲覀兊纳镄盘?hào)比智能體的電子信號(hào)要慢一些。這里有一個(gè)反應(yīng)時(shí)間測試的例子,鏈接乳腺,你可以自己動(dòng)手試試:
https://faculty.washington.edu/chudler/java/redgreen.html
因此,我們智能體的卓越表現(xiàn)可能要?dú)w功于它們更快的視覺處理和運(yùn)動(dòng)控制能力。然而,通過人為地降低它們攻擊的準(zhǔn)確率、增加其反應(yīng)時(shí)間,我們發(fā)現(xiàn)這只是它們?nèi)〉贸晒Φ谋姸嘁蛩刂械囊粋€(gè)。在更加深入的研究中,我們訓(xùn)練了內(nèi)置 1/4 秒(267 毫秒)延遲的智能體。也就是說,這些智能體在觀察世界之前會(huì)有 267 毫秒的滯后,這與統(tǒng)計(jì)出的人類電子游戲玩家的反應(yīng)時(shí)間相當(dāng)。盡管如此,這些帶有反應(yīng)延遲的智能體仍然比人類玩家的表現(xiàn)要好:人類玩家中的強(qiáng)者在智能體面前只有 21% 的勝率。

人類玩家在反應(yīng)延遲的智能體面前,其勝率也很低,這說明即使反應(yīng)延遲的時(shí)間與人類相當(dāng),智能體也比人類玩家表現(xiàn)好。除此之外,通過觀察人類玩家和反應(yīng)延遲的智能體的玩游戲情況,我們可以看到二者發(fā)生攻擊事件的數(shù)目相當(dāng),說明這些智能體在這個(gè)方面與人類相比并不具有優(yōu)勢。
通過無監(jiān)督學(xué)習(xí),我們構(gòu)建了智能體和人類的原型行為模式,發(fā)現(xiàn)智能體實(shí)際上是學(xué)習(xí)到了人類相類似的行為,例如跟隨隊(duì)友以及在對手的基地蹲點(diǎn)。

示例中,經(jīng)過訓(xùn)練的三個(gè)智能體可以自動(dòng)發(fā)現(xiàn)行為。
通過強(qiáng)化學(xué)習(xí)和種群水平的演進(jìn),這些行為逐漸出現(xiàn)在訓(xùn)練過程中。而隨著智能體學(xué)會(huì)通過更加復(fù)雜的方式進(jìn)行協(xié)作,就會(huì)逐漸淘汰掉像跟隨隊(duì)友這樣的簡單行為。
FTW 智能體種群的訓(xùn)練過程。左上角:30 個(gè)智能體在訓(xùn)練和相互演化的過程中得到的 Elo 等級(jí)評分。右上角:這些演化事件的遺傳樹。底部的圖片顯示了在智能體的訓(xùn)練過程中知識(shí)、內(nèi)部獎(jiǎng)勵(lì)以及行為概率的變化情況。
未來的研究
盡管本論文重點(diǎn)關(guān)注的是 CTF,但我們的工作對于科學(xué)研究的貢獻(xiàn)是通用的,我們非常樂見其他研究者基于我們的技術(shù)在各不相同的復(fù)雜環(huán)境中開發(fā)相關(guān)技術(shù)。自從最初發(fā)布這些實(shí)驗(yàn)結(jié)果以來,我們看到了許多人成功地將這些方法擴(kuò)展到了「Quake III Arena」的完整游戲中,包括專業(yè)的游戲地圖、更多 CTF 之外的多玩家游戲模式,以及更多的道具拾撿和使用動(dòng)作。初步的結(jié)果表明,智能體可以在多種游戲模式和多張地圖中表現(xiàn)出很強(qiáng)的競爭力,并且在測試比賽中開始逐漸對我們?nèi)祟愌芯空叩募寄芴岢隽颂魬?zhàn)。實(shí)際上,這項(xiàng)工作中提出的一些概念(如基于種群的多智能體強(qiáng)化學(xué)習(xí)),構(gòu)成了我們針對「星際爭霸 2」設(shè)計(jì)的「AlphaStar agent」智能體(https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/)的基石。
在另外兩個(gè)「Quake III Arena」多人游戲模式下的完整版錦標(biāo)賽地圖上進(jìn)行游戲的智能體:「Future Crossing」地圖上的收割者模式,以及「Ironwood」地圖上的單旗奪旗模式
總的來說,這項(xiàng)工作強(qiáng)調(diào)了多智能體訓(xùn)練在推動(dòng)人工智能發(fā)展上顯示的潛力:利用多智能體訓(xùn)練所提供的自然學(xué)習(xí)信息,同時(shí)也能促使我們開發(fā)出甚至可以與人類合作的魯棒的智能體。
- 論文下載地址:https://arxiv.org/abs/1807.01281
- 完整的補(bǔ)充講解視頻:https://youtu.be/dltN4MxV1RI
來源 | 雷鋒網(wǎng)
作者 | MrBear
編輯 | 幸麗娟









