
近年來,隨著預訓練語言模型技術引發人工智能領域性能革命,大規模預訓練模型技術的成熟標志著“大模型時代”的到來。然而在大模型的具體應用與落地中,卻存在著“訓練難、微調難、應用難”三大挑戰。
為此,清華大學自然語言處理實驗室和智源研究院語言大模型加速技術創新中心共同支持發起了OpenBMB(Open Lab for Big Model Base)開源社區,旨在打造大規模預訓練語言模型庫與相關工具,加速百億級以上大模型的訓練、微調與推理,降低大模型使用門檻,實現大模型的標準化、普及化和實用化。
為了讓大模型飛入千家萬戶,OpenBMB開源社區、鵬城實驗室,以及OpenI啟智社區已攜手進行國內獨家開源合作,將共同推動大模型在人工智能開源領域的發展與普及。目前,OpenBMB社區已正式入駐并將其部分模型套件開源部署至OpenI啟智社區,計劃通過OpenI啟智社區進行代碼和數據集的開放管理,匯聚更多開源開發者的力量,以及基于鵬城云腦科學裝置提供的算力資源,進一步推進OpenBMB系列大模型套件的開發與訓練。
歡迎大家訪問OpenBMB開源社區主頁鏈接,參與代碼貢獻與支持社區建設。
https://git.openi.org.cn/OpenBMB
1、OpenBMB開源社區成立背景:從大數據到大模型
近年來人工智能和深度學習技術飛速發展,極大改變了我們的日常工作與生活。伴隨人類社會信息化產生海量數據,人工智能技術能夠有效學習數據的分布與特征,對數據進行深入分析并完成復雜智能任務,產生巨大的經濟與社會價值,人類社會步入了“大數據時代”。
當前人工智能算法的典型流程為:準備數據、訓練模型和部署模型。其挑戰在于,針對給定任務人工標注訓練數據注費時費力,數據規模往往有限,需要承擔算法性能不達標、模型泛化能力差等諸多風險,導致人工智能面臨研發周期長、風險大、投入成本高的困局,阻礙了人工智能算法的落地與推廣。
2018年預訓練語言模型技術橫空出世,形成了“預訓練-微調”的新研發范式,極大地改變了上述困局。在這個新范式下,我們可以非常容易地搜集大規模無標注語料,采用自監督學習技術預訓練語言模型;然后可以利用特定下游任務對應的訓練數據,進一步微調更新模型參數,讓該模型掌握完成下游任務的能力。大量研究結果證明,預訓練語言模型能夠在自然語言處理等領域的廣大下游任務上取得巨大的性能提升,并快速成長為人工智能生態中的基礎設施。
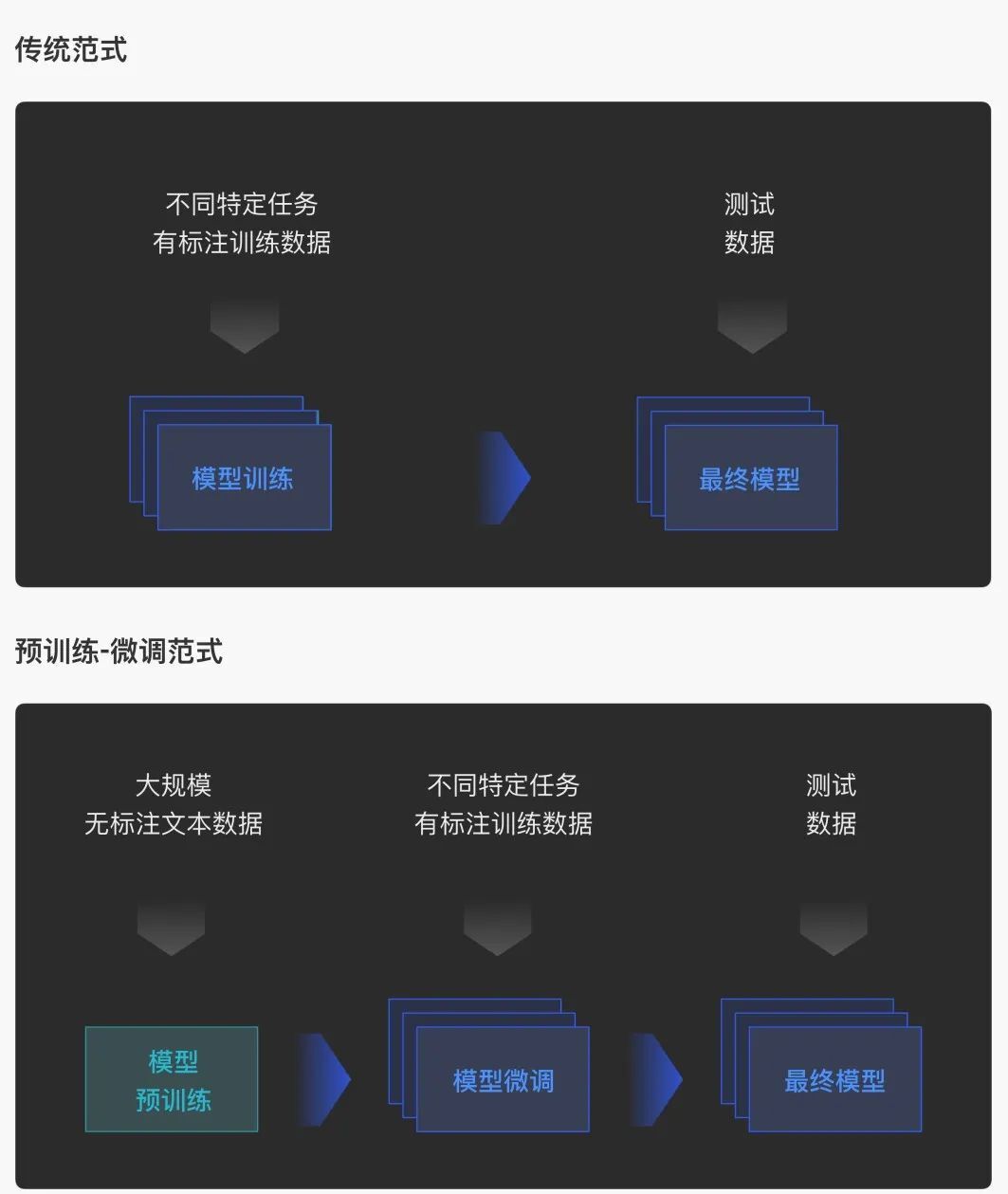
預訓練 – 微調范式對比傳統范式
通過充分利用互聯網上近乎無窮的海量數據,預訓練模型正在引發一場人工智能的性能革命。研究表明,更大的參數規模為模型性能帶來質的飛躍。對十億、百億乃至千億級超大模型的探索成為業界的熱門話題,引發國內外著名互聯網企業和研究機構的激烈競爭,將模型規模和性能不斷推向新的高度。除Google、OpenAI等國外知名機構外,近年來國內相關研究機構與公司也異軍突起,形成了大模型的研究與應用熱潮。圍繞大模型展開的"軍備競賽"日益白熱化,成為對海量數據、并行計算、模型學習和任務適配能力的全方位考驗,人工智能進入“大模型時代”。
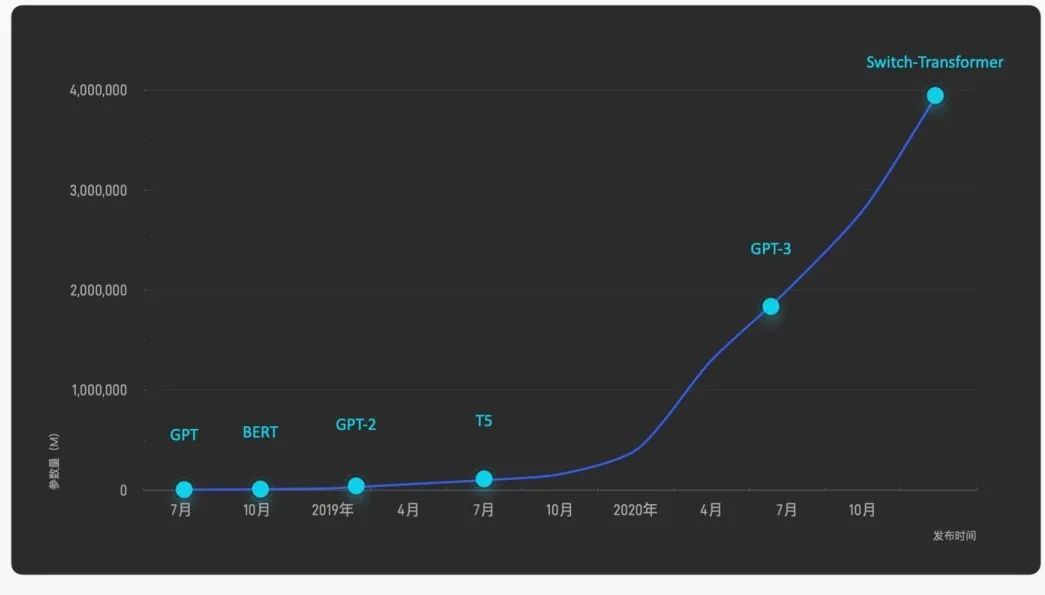
國內外知名機構在大模型訓練中持續投入
然而在“大模型時代”,因為大模型巨大的參數量和算力需求,在大范圍內應用大模型仍然存在著較大的挑戰。如何讓更多開發者方便享用大模型,如何讓更多企業廣泛應用大模型,讓大模型不再“大”不可及,是實現大模型可持續發展的關鍵。與普通規模的深度學習模型相比,大模型訓練與應用需要重點突破三大挑戰:
? 訓練難:訓練數據量大,算力成本高。
? 微調難:微調參數量大,微調時間長。
? 應用難:推理速度慢,響應時間長,難以滿足線上業務需求。
為了讓大模型技術更好地普及應用,針對這些挑戰,清華大學自然語言處理實驗室和智源研究院語言大模型加速技術創新中心成立了OpenBMB開源社區。
2、OpenBMB能力體系:應用便捷的大規模預訓練模型庫
謀定而動,OpenBMB將從數據、工具、模型、協議四個層面構建應用便捷、能力全面、使用規范的大規模預訓練模型庫。
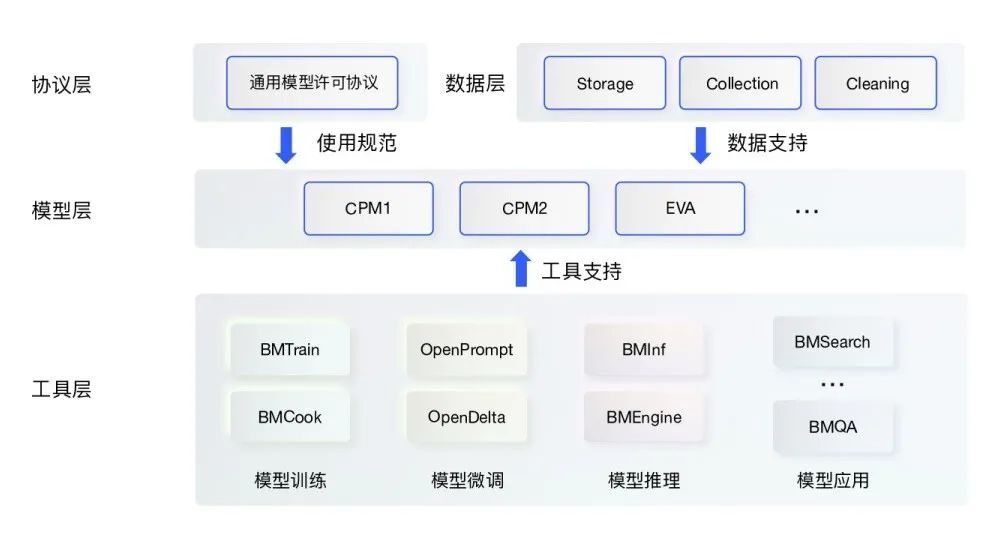
OpenBMB 能力體系
OpenBMB能力體系具體包括:
? 數據層:構建大規模數據自動收集、自動清洗、高效存儲模塊與相關工具,為大模型訓練提供數據支持。
? 工具層:聚焦模型訓練、模型微調、模型推理、模型應用四個大模型主要場景,推出配套開源工具包,提升各環節效率,降低計算和人力成本。
? 模型層:構建OpenBMB工具支持的開源大模型庫,包括BERT、GPT、T5等通用大模型和CPM、EVA、GLM等悟道開源大模型,并不斷完善添加新模型,形成覆蓋全面的模型能力。
? 協議層:發布通用模型許可協議,規范與保護大模型發布使用過程中發布者與使用者權利與義務,目前協議初稿已經開源(https://www.openbmb.org/license)。
大模型相關工具在OpenBMB能力體系中發揮著核心作用。OpenBMB將努力建設大模型開源社區,團結廣大開發者不斷完善大模型從訓練、微調、推理到應用的全流程配套工具。基于發起人團隊前期工作,OpenBMB設計了大模型全流程研發框架,并初步開發了相關工具,這些工具各司其職、相互協作,共同實現大模型從訓練、微調到推理的全流程高效計算。
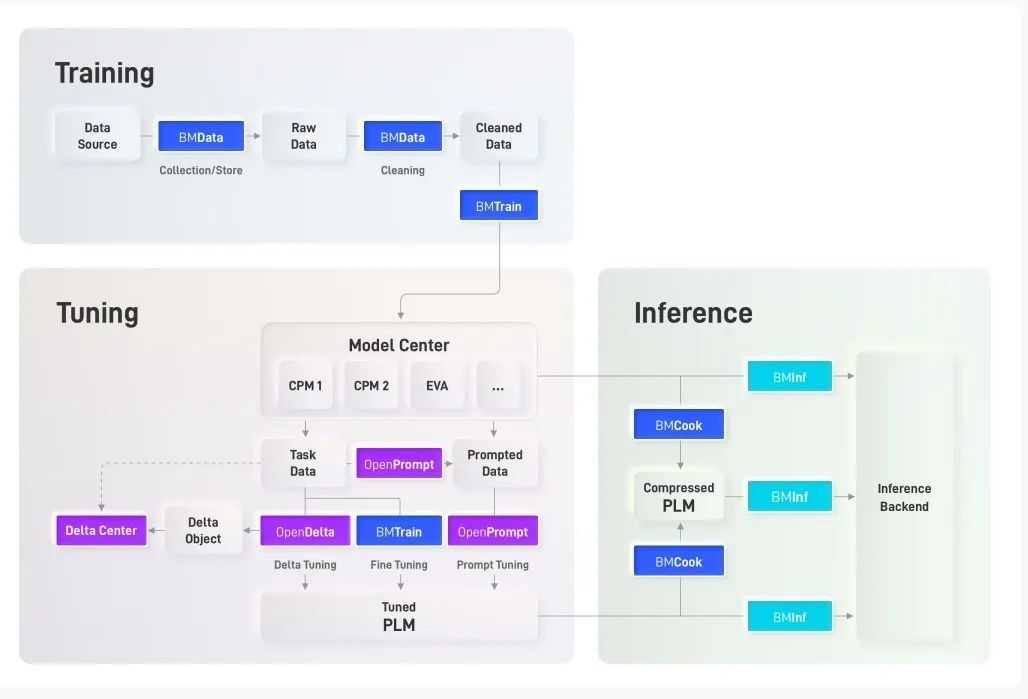
OpenBMB 工具架構圖
3、OpenBMB工具:解決大模型三大難題
模型訓練套件
BMTrain:大模型訓練“發動機”。BMTrain進行高效的大模型預訓練與微調。與DeepSpeed等框架相比,BMTrain訓練模型成本可節省90%。
開源地址如下:
https://git.openi.org.cn/OpenBMB/BMTrain
BMCook:大模型“瘦身”工具庫。BMCook進行大模型高效壓縮,提高運行效率。通過量化、剪枝、蒸餾、專家化等算法組合,可保持原模型90%+效果,模型推理加速10倍。
開源地址如下:
https://git.openi.org.cn/OpenBMB/BMCook
BMData:大模型“原料”收集器。BMData進行高質量數據清洗、處理與存儲,為大模型訓練提供全面、綜合的數據支持。
模型微調套件
OpenPrompt:大模型提示學習利器。OpenPrompt提供統一接口的提示學習模板語言,2021年發布以來在國外某開源社區獲得1.3k星標,每周訪問量10k+。
OpenDelta:“小”參數撬動“大”模型。OpenDelta進行參數高效的大模型微調,僅更新極少參數(小于5%)即可達到全參數微調的效果。
Delta Center:“人人為我,我為人人” – Delta Object分享中心。Delta Center提供Delta Object的上傳、分享、檢索、下載功能,鼓勵社區開發者共享大模型能力。
模型推理套件
BMInf:千元級顯卡玩轉大模型推理。BMInf實現大模型低成本高效推理計算,使用單塊千元級顯卡(GTX 1060)即可進行百億參數大模型推理。2021年發布以來在國外某開源社區獲得200+星標。
開源地址如下:
https://git.openi.org.cn/OpenBMB/BMInf
近期,OpenBMB開源社區已將部分完成開發的推理套件BMInf、訓練套件BMCook和BMTrain上傳與開源至OpenI啟智社區,而后續也會將全部工具開源上來。未來,OpenBMB將依托自有開源社區和OpenI啟智社區開源的力量,與廣大開發者一道共同打磨和完善大模型相關工具,助力大模型應用與落地。期待廣大開發者關注和貢獻OpenBMB!
4、OpenBMB團隊介紹:國內頂尖高校科研力量
OpenBMB開源社區由清華大學自然語言處理實驗室和智源研究院語言大模型加速技術創新中心共同支持發起。
發起團隊擁有深厚的自然語言處理和預訓練模型研究基礎,曾最早提出知識指導的預訓練模型ERNIE并發表在自然語言處理頂級國際會議ACL 2019上,累計被引超過600次,被學術界公認為融合知識的預訓練語言模型的代表方法,被美國國家醫學院院士團隊用于研制醫學診斷領域的自動問答系統;團隊依托智源研究院研發的“悟道·文源”中文大規模預訓練語言模型CPM-1、CPM-2,參數量最高達到1980億,在眾多下游任務中取得優異性能;團隊近年來圍繞模型預訓練、提示學習、模型壓縮技術等方面在頂級國際會議上發表了數十篇高水平論文,2022年面向生物醫學的預訓練模型KV-PLM發表在著名綜合類期刊Nature Communications上,并入選該刊亮點推薦文章,相關論文列表詳見文末。
團隊還有豐富的自然語言處理技術的開源經驗,發布了OpenKE、OpenNRE、OpenNE等一系列有世界影響力的工具包,在GitHub上累計獲得超過5.8萬星標,位列全球機構第148位,曾獲教育部自然科學一等獎、中國中文信息學會錢偉長中文信息處理科學技術獎一等獎等成果獎勵。
發起團隊面向OpenBMB開源社區研制發布的BMInf、OpenPrompt、OpenDelta等工具包已陸續發表在自然語言處理頂級國際會議ACL 2022上。
OpenBMB主要發起人介紹
孫茂松
清華大學計算機系教授,智源研究院自然語言處理方向首席科學家,清華大學人工智能研究院常務副院長,清華大學計算機學位評定分委員會主席,歐洲科學院外籍院士。主要研究方向為自然語言處理、人工智能、社會人文計算和計算教育學。在人工智能領域的著名國際期刊和會議發表相關論文400余篇,Google Scholar統計引用超過2萬次。曾獲全國優秀科技工作者、教育部自然科學一等獎、中國中文信息學會錢偉長中文信息處理科學技術獎一等獎,享受國務院政府特殊津貼。
劉知遠
清華大學計算機系副教授,智源青年科學家。主要研究方向為自然語言處理、知識圖譜和社會計算。在人工智能領域著名國際期刊和會議發表相關論文200余篇,Google Scholar統計引用超過2萬次。曾獲教育部自然科學一等獎(第2完成人)、中國中文信息學會錢偉長中文信息處理科學技術獎一等獎(第2完成人)、中國中文信息學會漢王青年創新獎,入選國家青年人才計劃、2020年Elsevier中國高被引學者、《麻省理工科技評論》中國區35歲以下科技創新35人榜單、中國科協青年人才托舉工程。
韓旭
清華大學計算機系博士生,研究方向為自然語言處理、預訓練語言模型和知識計算,在人工智能領域著名國際期刊和會議ACL、EMNLP上發表多篇論文,悟道·文源中文預訓練模型團隊骨干成員,CPM-1、CPM-2、ERNIE的主要作者之一。曾獲2011年全國青少年信息學競賽金牌(全國40人)、國家獎學金、清華大學“蔣南翔”獎學金、清華大學“鐘士模”獎學金、微軟學者獎學金(亞洲12人)、清華大學優良畢業生等榮譽。
曾國洋
清華大學計算機系畢業生,智源研究院語言大模型加速技術創新中心副主任。擁有豐富人工智能項目開發與管理經驗,悟道·文源中文預訓練模型團隊骨干成員,BMTrain、BMInf的主要作者之一。曾獲2015年全國青少年信息學競賽金牌(全國50人)、亞太地區信息學競賽金牌、清華大學挑戰杯一等獎、首都大學生挑戰杯一等獎。
丁寧
清華大學計算機系博士生,研究方向為機器學習、預訓練語言模型和知識計算,在人工智能領域著名國際期刊和會議ICLR、ACL、EMNLP上發表多篇論文,悟道·文源中文預訓練模型團隊骨干成員,OpenPrompt、OpenDelta的主要作者之一。曾獲國家獎學金、清華大學“清峰”獎學金、百度獎學金(全國10人)等榮譽。
張正彥
清華大學計算機系博士生,研究方向為自然語言處理和預訓練語言模型,在人工智能領域著名國際期刊和會議ACL、EMNLP、TKDE上發表多篇論文,悟道·文源中文預訓練模型團隊骨干成員,CPM-1、CPM-2、ERNIE的主要作者之一。曾獲國家獎學金、清華大學優良畢業生、清華大學優秀本科畢業論文等榮譽。
結語
OpenI啟智社區是以鵬城云腦科學裝置及軟件開發群智范式為基礎,由新一代人工智能產業技術創新戰略聯盟(AITISA)組織產學研用協作共建共享的開源平臺與社區。
無論你正在從事大模型研究,研發大模型應用,還是對大模型技術充滿興趣,歡迎來OpenI啟智社區使用OpenBMB開源工具和模型庫。OpenBMB開源社區推崇簡捷,追求極致,相信數據與模型的力量。歡迎志同道合的你加入,共同為大模型應用落地添磚加瓦,早日讓大模型飛入千家萬戶。
OpenBMB相關鏈接
? 開源主頁:
https://git.openi.org.cn/OpenBMB
? 官方網站:
https://www.openbmb.org
? 交流QQ群:
735930538
? 微博:
http://weibo.cn/OpenBMB
? 郵箱:
openbmb@gmail.com
? 知乎:
https://www.zhihu.com/people/OpenBMB
? Twitter:
https://twitter.com/OpenBMB
附錄 團隊論文發布列表
1. Zhengyan Zhang, Xu Han, Zhiyuan Liu et al. ERNIE: Enhanced Language Representation with Informative Entities. ACL 2019.
2. Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu et al. KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation. TACL 2021.
3. Yujia Qin, Yankai Lin, Ryuichi Takanobu et al. ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning. ACL-IJCNLP 2021.
4. Xu Han, Zhengyan Zhang, Ning Ding et al. Pre-Trained Models: Past, Present and Future. AI Open 2021.
5. Zhengyan Zhang, Xu Han, Hao Zhou et al. CPM: A Large-scale Generative Chinese Pre-trained Language Model. AI Open 2021.
6. Zheni Zeng, Yuan Yao, Zhiyuan Liu, Maosong Sun. A Deep-learning System Bridging Molecule Structure and Biomedical Text with Comprehension Comparable to Human Professionals. Nature Communications 2022.
7. Ning Ding, Yujia Qin, Guang Yang et al. Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models. Arxiv 2022.
8. Zhengyan Zhang, Yuxian Gu, Xu Han et al. CPM-2: Large-scale Cost-effective Pre-trained Language Models. AI Open 2022.
9. Ganqu Cui, Shengding Hu, Ning Ding et al. Prototypical Verbalizer for Prompt-based Few-shot Tuning. ACL 2022.
10. Shengding Hu, Ning Ding, Huadong Wang et al. Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification. ACL 2022.
11. Yujia Qin, Jiajie Zhang, Yankai Lin et al. ELLE: Efficient Lifelong Pre-training for Emerging Data. Findings of ACL 2022.
12. Yuan Yao, Bowen Dong, Ao Zhang et al. Prompt Tuning for Discriminative Pre-trained Language Models. Findings of ACL 2022.
13. Ning Ding, Shengding Hu, Weilin Zhao et al. OpenPrompt: An Open-source Framework for Prompt-learning. ACL 2022 Demo.
14. Han Xu, Guoyang Zeng, Weilin Zhao et al. BMInf: An Efficient Toolkit for Big Model Inference and Tuning. ACL 2022 Demo.









