來自微軟亞洲研究院(MSRA)自然語言處理(NLP)小組和微軟 Redmond 語言對話研究小組的一組研究人員目前在斯坦福大學(xué)組織的對話問答(COQA)挑戰(zhàn)中處于領(lǐng)先位置。在這一挑戰(zhàn)中,衡量機(jī)器的方法是其理解文本段落和回答會話中出現(xiàn)的一系列相互關(guān)聯(lián)的問題的能力大小。微軟目前是唯一一個(gè)在其模型性能上達(dá)到人類同等水平的團(tuán)隊(duì)。
CoQA 是一個(gè)大型的會話問答數(shù)據(jù)集,由來自不同領(lǐng)域的一組文章上的會話問題組成。MSRA NLP 團(tuán)隊(duì)使用斯坦福問答數(shù)據(jù)集(SQuAD)在單輪問答上達(dá)到了人類同等水平,這是一個(gè)新的里程碑。與 SQuAD 相比,CoQA 中的問題更具對話性,為了確保答案看起來自然,它可以是自由格式的文本。
CoQA 中的問題非常簡短,可以模仿人類的對話。此外,第一個(gè)問題之后的每個(gè)問題都是基于前面的問題的,這使得機(jī)器更難解析簡短的問題。例如,假設(shè)你問一個(gè)系統(tǒng),「誰是微軟的創(chuàng)始人?」,當(dāng)你繼續(xù)問第二個(gè)問題「他什么時(shí)候出生的?」時(shí),你需要理解你仍然在談?wù)摵椭跋嗤脑掝}。

為了更好地測試現(xiàn)有模型的泛化能力,CoQA 從收集了七個(gè)不同領(lǐng)域的數(shù)據(jù):兒童故事、文學(xué)、初高中英語考試、新聞、維基百科、Reddit 和科學(xué)。前五個(gè)用于訓(xùn)練、開發(fā)和測試集,后兩個(gè)僅用于測試集。CoQA 使用 F1 度量來評估性能。F1 度量衡量的是預(yù)測內(nèi)容和真實(shí)答案答案之間的平均重疊詞。域內(nèi) F1 根據(jù)訓(xùn)練集所在域的測試數(shù)據(jù)進(jìn)行評分;域外 F1 根據(jù)不同域的測試數(shù)據(jù)進(jìn)行評分。總的 F1 度量值是整個(gè)測試集的最終得分。
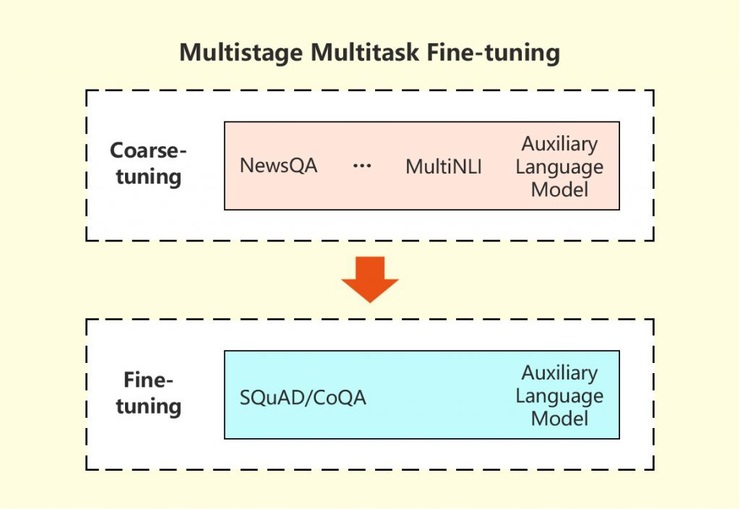
微軟研究人員所采用的方法使用了一種特殊的策略,即利用從幾個(gè)相關(guān)任務(wù)中獲得的信息來改進(jìn)目標(biāo)機(jī)器閱讀理解(MRC)任務(wù)。在多階段、多任務(wù)、微調(diào)方法中,研究人員首先在多任務(wù)設(shè)置下從相關(guān)任務(wù)中學(xué)習(xí) MRC 相關(guān)背景信息,然后對目標(biāo)任務(wù)的模型進(jìn)行微調(diào)。語言建模在這兩個(gè)階段都作為輔助任務(wù)使用,以幫助減少會話問答模型的過度擬合。實(shí)驗(yàn)證明了該方法的有效性,其在 CoQA 挑戰(zhàn)中的強(qiáng)大性能也證明了這一點(diǎn)。

根據(jù) CoQA 排行榜,微軟研究人員于 2019 年 3 月 29 日提交的系統(tǒng)得分達(dá)到 89.9/88.0/89.4,分別作為其領(lǐng)域內(nèi)、領(lǐng)域外和整體 F1 分?jǐn)?shù)。而在面對同一組會話問題和答案,人的表現(xiàn)得分為 89.4/87.4/88.8。
這一成就標(biāo)志著搜索引擎(如 Bing)和智能助手(如 Cortana)在與人互動和以更自然的方式提供信息方面取得了重大進(jìn)展,就像人們相互交流一樣。然而,一般的機(jī)器閱讀理解和問答仍然是自然語言處理中未解決的問題。為了進(jìn)一步擴(kuò)大機(jī)器理解和生成自然語言的能力邊界,團(tuán)隊(duì)將繼續(xù)致力于生成更強(qiáng)大的預(yù)訓(xùn)練模型。
來源 | 雷鋒網(wǎng)
作者 | 王雪佩









